

Mina is a little different. And we’re proud of that. But it can be a source of confusion. In this article, we’ll give a high-level overview of how state and computation works in zkApps powered by o1js and the Mina protocol, why certain atypical design patterns are necessary, and how this presents unique opportunities.
In a traditional web2 architecture, applications typically have unrestricted access to a private database of some kind. They perform computation and manipulate state directly. This is usually enabled by a permission scheme, often managed at infrastructure level through environment variables or private networks. These credentials specify which processes or runtimes are allowed to alter state. This means that, even if the infrastructure is distributed, computation and state are conceptually bound together in a trusted relationship. This is intuitive and reasonable in many cases.
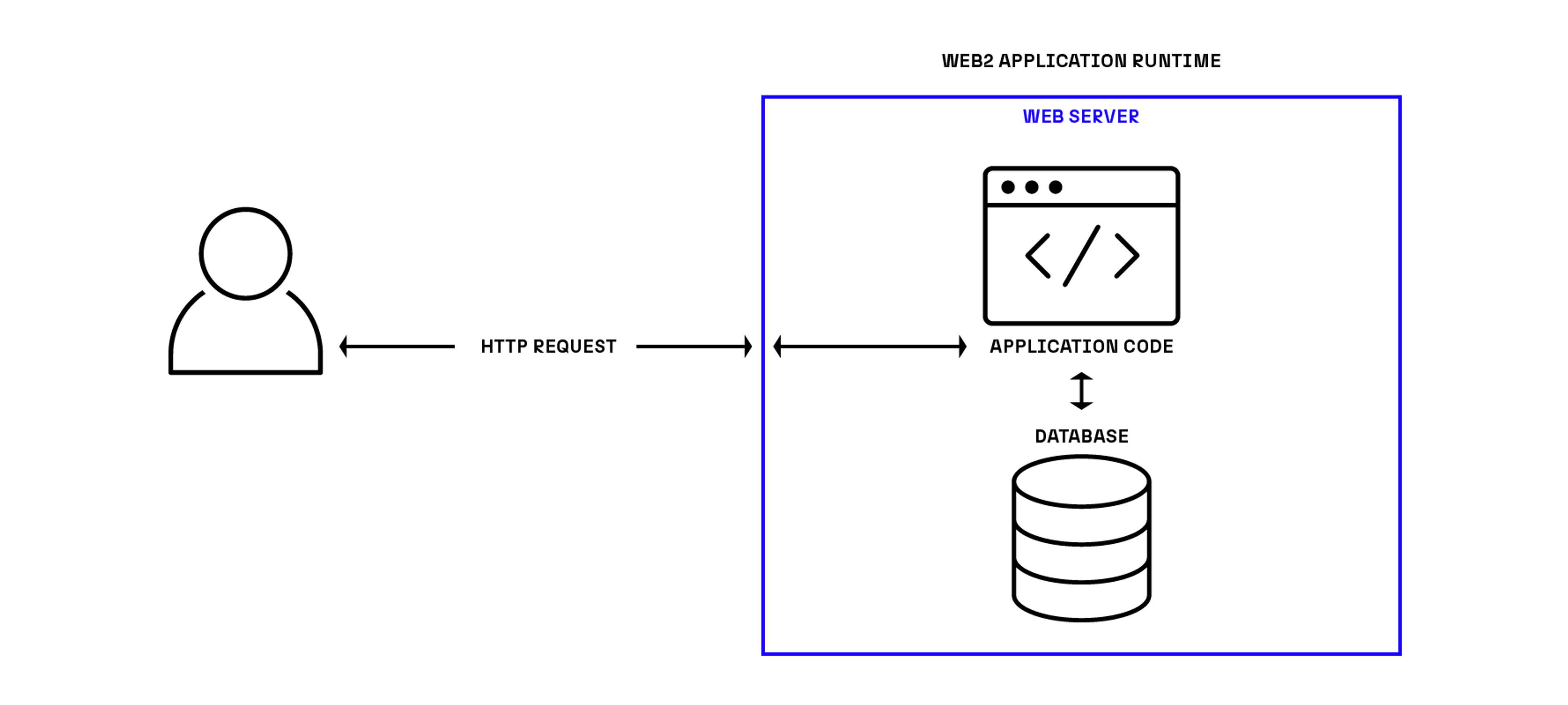
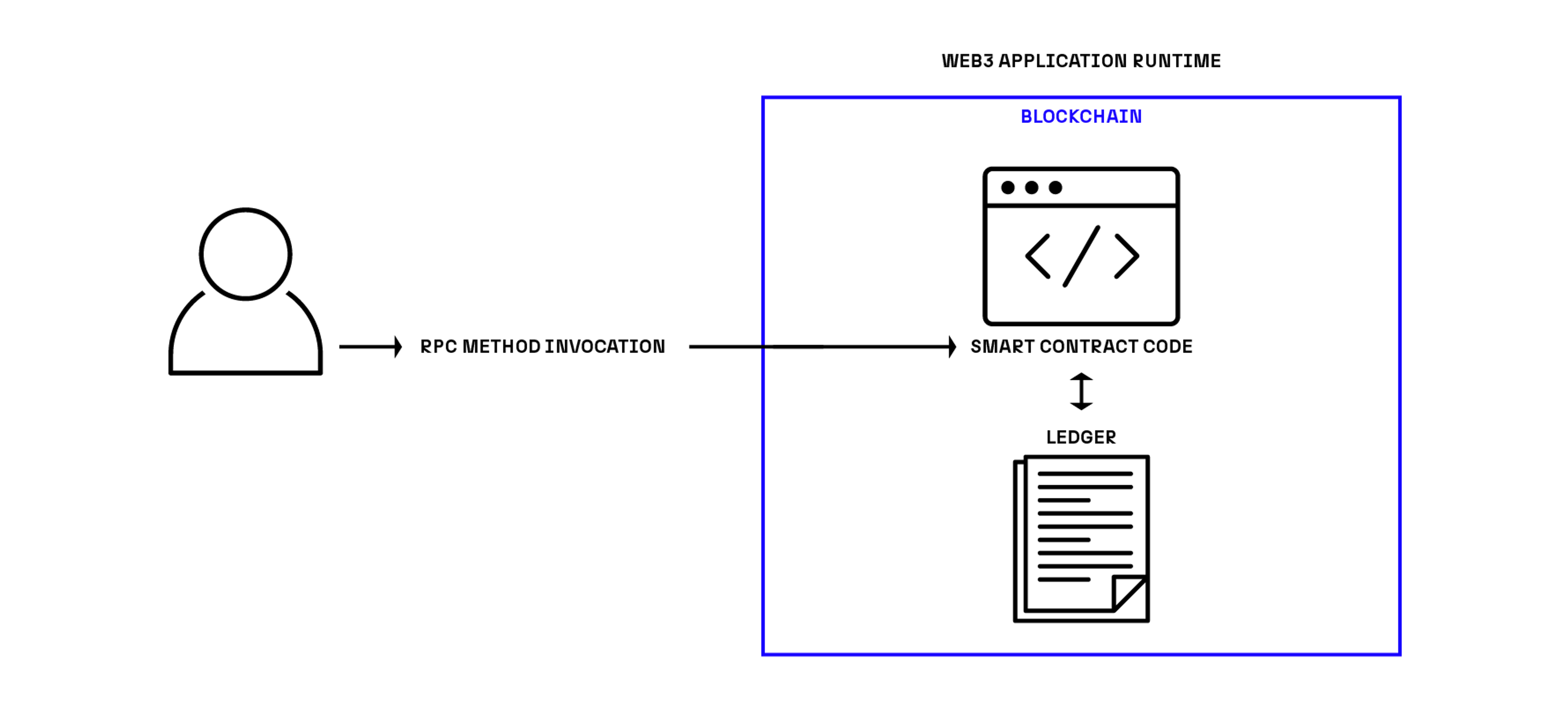
Web3 application architectures introduce public, disintermediated infrastructure. This is awesome but it doesn’t fundamentally alter this relationship between computation and state. These applications are still authorized to manipulate state by virtue of their locale; only code that runs on the blockchain can alter chain state. This is why we have Remote Procedure Call (RPC) method invocations and a gas model. We need to pay someone to run code in the right place so that it is allowed to alter state. It’s also why computation is duplicated across the network, resulting in immense waste and high transaction fees.
This is where Mina is different. Some state remains on the blockchain (and we’ll come back to this) but computation can be performed anywhere, as long as it is wrapped in a zero knowledge circuit. o1js allows developers to write applications that execute in an end-user’s browser but still reliably commit state to the public ledger. This is possible because state changes are authorized by proof of the originating computation’s validity, not the environment in which it is performed. We think this is pretty cool.
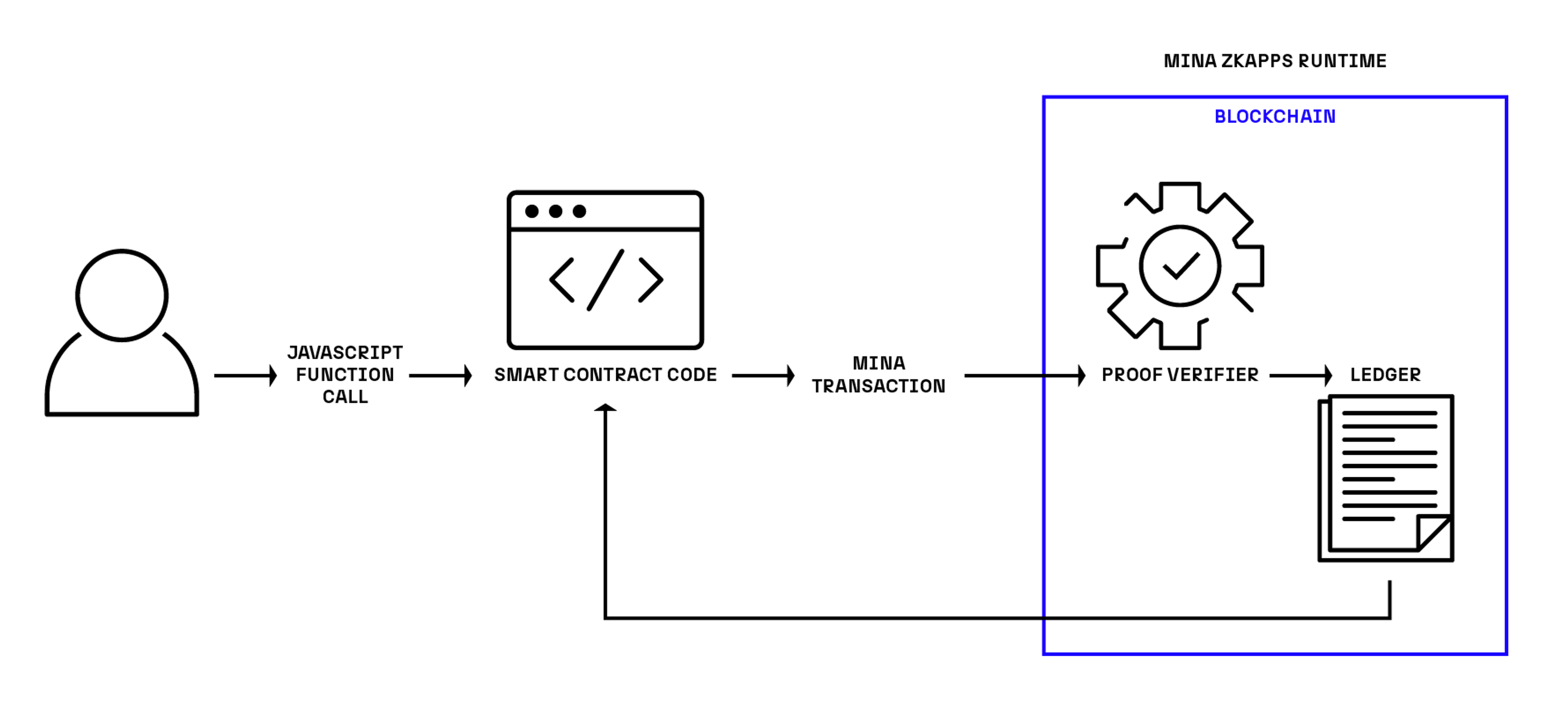
Let’s look at how this plays out in transactions. As we’ve already implied, they’re not RPCs. When someone interacts with a zkApp written in o1js, they are not asking the blockchain to run a smart contract method. By the time a transaction is submitted to Mina, the method has already been called. Application logic has already been performed inside a zero knowledge circuit. As long as all constraints defined in the circuit have been satisfied, the transaction simply describes a set of state changes that should be applied to the ledger, along with a zero knowledge proof that says those changes can be trusted. Mina Protocol simply verifies the proof and commits those changes to the ledger if the proof is valid. Computation and state have been disassociated. This makes every zkApp something of a rollup since network state changes are proven to have originated elsewhere. This is what enables fixed transaction fees for decentralized applications. It’s also why our unique Action/Reducer model is necessary to manage sequencing and concurrent access to state, so let’s dig into that.
Sequencing, Actions and Reducers
Sequencing presents a key challenge in any distributed system. In a blockchain, block producers determine the order of transactions. Application developers have no control over this order and must design their transactions to be commutative (processable in any order) because the computation that affects state occurs after transactions have been sequenced. In zkApps built on Mina, computation occurs off-chain, before transactions are even submitted. Commutativity isn’t enough because not only is the order out of our control, it hasn’t even been determined yet when computation occurs. So how can we change state without race conditions? With actions and a reducer. Instead of directly altering state, zkApps should publish an action that contains the data required to alter it later. This gives the protocol a chance to order those actions before they’re processed. A separate process - another method on the smart contract - then employs a reducer to consume those actions, process them, and commit the final state in another transaction. We’re basically splitting out the aggregation step and performing it after sequencing has been performed. It’s a bit like map/reduce in that sense.
Let’s unpack this idea of storing state a little further, since that’s also handled a bit differently. Each Mina smart contract account can hold eight arbitrary field elements. Each field is roughly 32 bytes in size. This may not seem like much, but consider that under the hood, Ethereum uses a similar mechanism with a single field (in the World State trie) that references an arbitrary amount of contract state stored elsewhere. That reference field is called storageRoot and, as the name suggests, holds the root hash of a trie containing all of the contract account’s stored state (the Account Storage trie). Each of the 8 field elements on a Mina contract account is like Ethereum’s storageRoot, able to hold commitments to an arbitrary amount of data stored elsewhere. Ethereum makes all of these additional state tries available as global network state and manages it for you (with gas costs). Mina, however, does not. You need to store your own data structures off-chain and commit to those structures in the on-chain account state fields. This is usually done by keeping the actual state in a Merkle tree and storing the root hash of that tree in one of the account fields. It’s basically the same mechanism but decoupled from the network. This allows for fixed transaction costs, regardless of the amount of storage used.
Proof of Everything
So why is any of this cool? It comes with a bit more effort for application developers, after all. What’s the payoff? We’ll need to take a step back to answer this. Mina is a proof verification layer at heart. We’ve just shown how that can be leveraged to achieve smart contract-like behavior with some really interesting properties like off-chain computation and fixed transaction fees but that’s only part of the picture. Let’s set that aside for a moment and look at the design more abstractly. zkApps on Mina give you, the developer, the ability to generate, sequence and verify proofs of things. Things like identity, inclusion in a community, signature schemes, or the rolled-up state of some other network. Any computation, really. And that’s super interesting. When you submit a zkApp transaction, Mina sequences your proofs and composes them with other proofs to create a single, aggregated verification of all facts submitted to the network thus far. We’re rolling your custom proofs up into further proofs that verify transaction application, block production, and ultimately the network state as a whole. Similar capabilities for recursive composability are in your hands too. This means you have a trustless, distributed, and decentralized way to create and sequence composable proofs. You can build apps that are both standalone statements of fact and fragments of a larger, verifiable computation created by the community at will. We think this is extremely cool, and presents immense possibilities that are yet to be discovered. It is a little different, sure. But we think it’s very powerful. And we can’t wait to see what you build with it.
Join the Mina community and explore our developer resources to help build a better future with Mina’s proof of everything.