

In this second technical entry in our series, we're finally ready to get down to the details of [Project Untitled] and how it will really work. If you missed them, check out our [Project Untitled] overview to revisit the core problem we're solving, or go here for our technical overview of the problem space in general. This entry will dive deeper into the cryptography backing the system, the fundamentals of the protocol design, and tie together how the system will look for each of the major actors. We'll also outline some of the remaining design work as we progress towards a full whitepaper.
Proof of state availability
At their core, modern zero knowledge proof systems are formed of 2 parts: a constraint definition that the data must satisfy, and an opening proof where the prover convinces the verifier that they have some polynomial that satisfies the constraints. To create an opening proof, you need to have the underlying data available, so we can re-use this system to prove that a state replication node is really providing access to the data that they claim to.
Concretely, if we want to check that somebody really does have access to some data, we can agree to split that data up into chunks, create polynomial commitments to those chunks, and then use an opening proof to get them to show that they still have the data. Of course, we need to make sure that they can’t create all of the proofs in advance: we want to guarantee that they have access to the data now. Instead of proving the opening directly, we can mix together the polynomial commitments using a random challenge and then open the result. This neatly achieves our goals, ensuring that a bad actor in the system could never generate the randomized values without having all of the necessary data.
Choosing a polynomial commitment scheme
To do this, our polynomial commitment scheme and opening proofs should have a few specific properties.
The first crucial property is that we can update multiple parts of our data chunks at the same time. To provide mutable state, this property is non-negotiable: updates to the data must be inexpensive for the system to be usable in practice.
Beyond this first property, but relatedly, we would like additive homomorphism to let us inexpensively calculate the random mix of the data chunks from our random challenge r:
C_mix = r . C_1 + r^2 . C_2 + …
data_mix[i] = r . data_1[i] + r^2 . data_2[i] + …
where C_mix is the commitment to the data in data_mix. Similarly, to be able to update data, we should be able to inexpensively build the updated commitments from the old commitments and the new data, where the time taken depends only on the size of the change, not the size of the full data. With these two properties in combination, we also get a third for free: applications only need to reason about the diff between the old and new state that they generate, and the resulting cheap commitment can be added to the old commitments to represent the new state.
By choosing a different random r periodically, a verifier can force the prover to retain the data: the prover will not be able to build the polynomial for data_mix at each new r without all of the input data available, and without the polynomial they cannot build an opening proof for the commitment C_mix.
While choosing an opening proof to complement the commitment scheme, we would also like to ensure that the verifiers of the protocol have a fixed amount of work to do. Importantly, the amount of work that the verifier has to do should not vary based on the amount of chunks that are stored. To achieve this, we would like an opening scheme that can be verified in batches, one that can handle the commitment construction proof at the same time as the state availability proof, and that is also flexible enough to handle ‘update proofs’ where diffs are submitted.
Luckily, this is exactly the kind of proof system that o1Labs has already built for Mina! With the extra added bonus of a universal transparent set-up, Kimchi+Pickles provide a solid base for us to build this protocol on.
Some readers will also have noticed that parts of this protocol bear some similarities to Nova-style folding schemes. We’ve noticed this too: the potential to use Arrabiata – the Nova-inspired folding scheme we’re building on top of kimchi – is not lost on us, and we will be applying it liberally to make sure everything is as fast as possible!
How would a decentralized system look?
While this protocol works seamlessly for two-party interactions, decentralizing it presents unique challenges. We think this is an important step: decentralized, trustless applications require decentralized, trustless state. In particular, we know it is important to achieve censorship resistance and permissionlessness in addition to mutable state access so that developers can rely on these properties throughout their application. While decentralization brings some additional challenges, we also see potential for more powerful incentive models, where the system can enforce the good behavior of all actors.
With some careful design, we can achieve the simplest possible interactions currently supported by host blockchains, with a path to even more simplicity as they integrate more tightly with [Project Untitled].
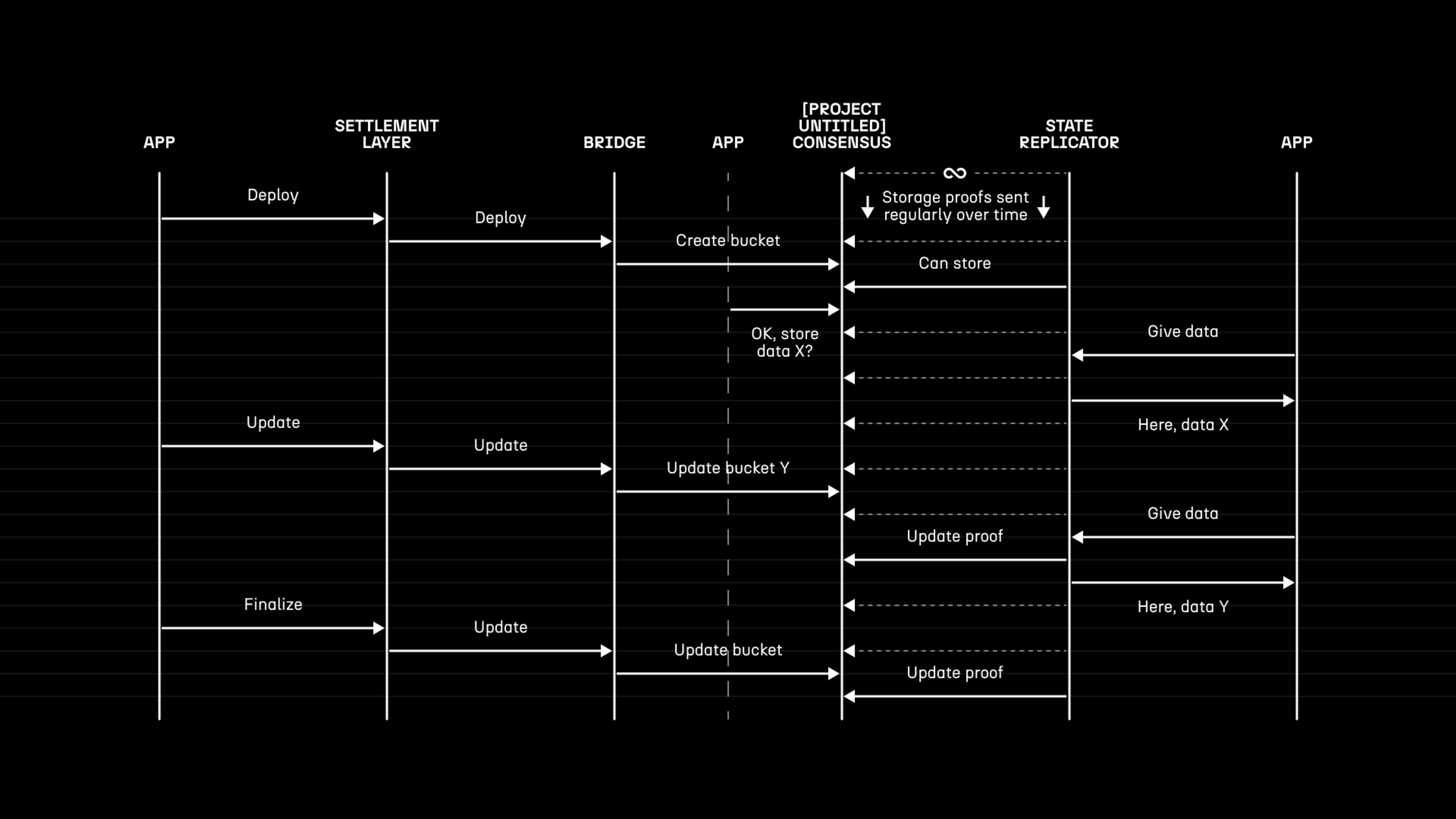
This interaction diagram shows how actions flow from the settlement layer to [Project Untitled], with minimal involvement from the application. Notice also that the app can interact with [Project Untitled] at any time to access its state, so that any user and any execution environment has an equal opportunity in the true spirit of decentralization. The minimum set of actions that need to be recorded on the bridge are the write operations, and we’re pleased to have a design that we believe will achieve exactly that.
Deployment
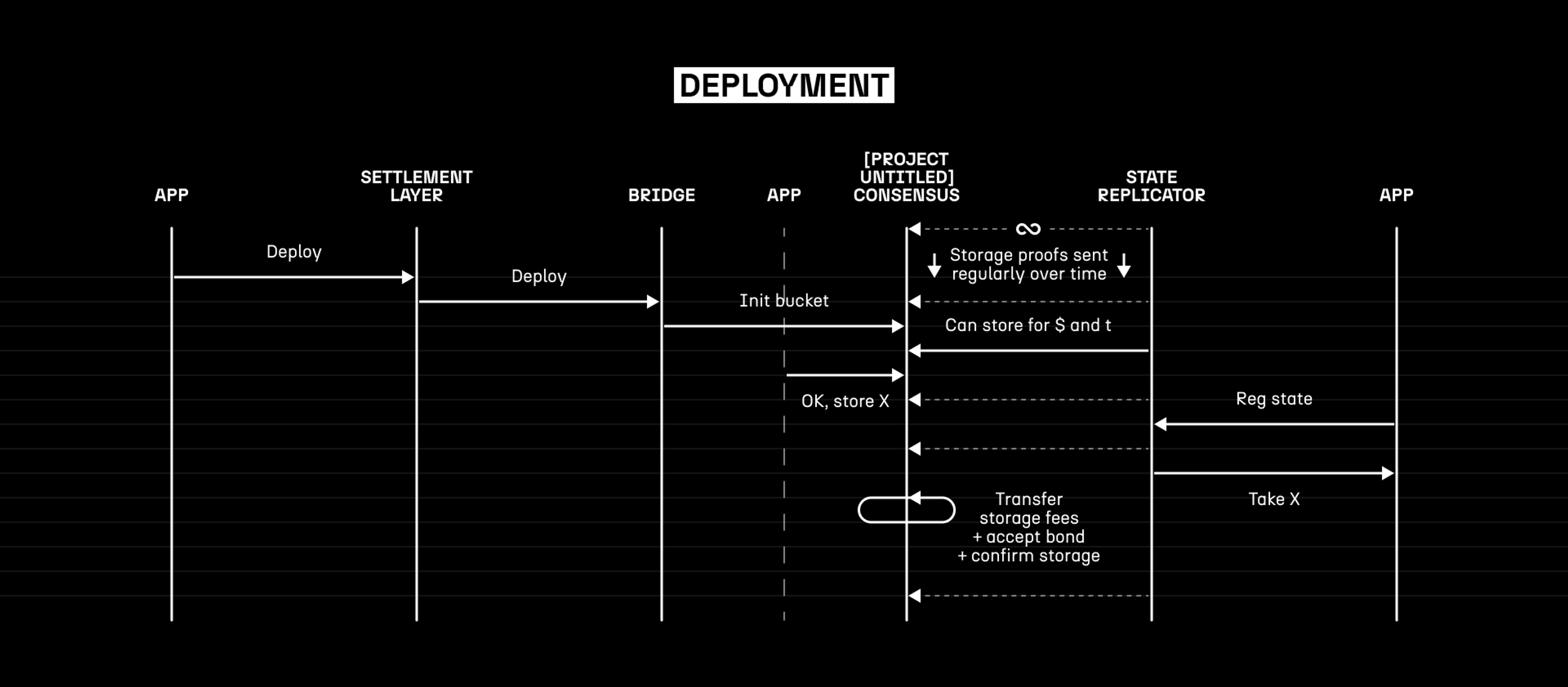
The most complex stage of the protocol is the initialisation of the [Project Untitled] state buckets. At this stage, the initial request for some state space is sent, an on-chain negotiation takes place, and – once a deal is made – the nodes will begin to download the data to set up the initial state bucket. Once the data has been received and the first storage proof is submitted, the replicator’s bond will be locked on-chain to enable slashing, and they will start producing storage proofs in exchange for the agreed-upon payment rate.
For extra confidence, we believe that some applications will want to request multiple replicas of their state, to provide additional protections against loss of data. There’s an interesting technique where we can store some encoding of the state that is (even without encoding) expensive to generate so that it is cheaper to store the encoded data than re-compute it, but inexpensive to recover the data from so that the data is easily accessible. Augmenting this with a system for cheap updates after the initial storage pass allows us to have the best of all worlds: knowing that the data really is replicated, but maintaining all of the other important properties of the system.
Updates
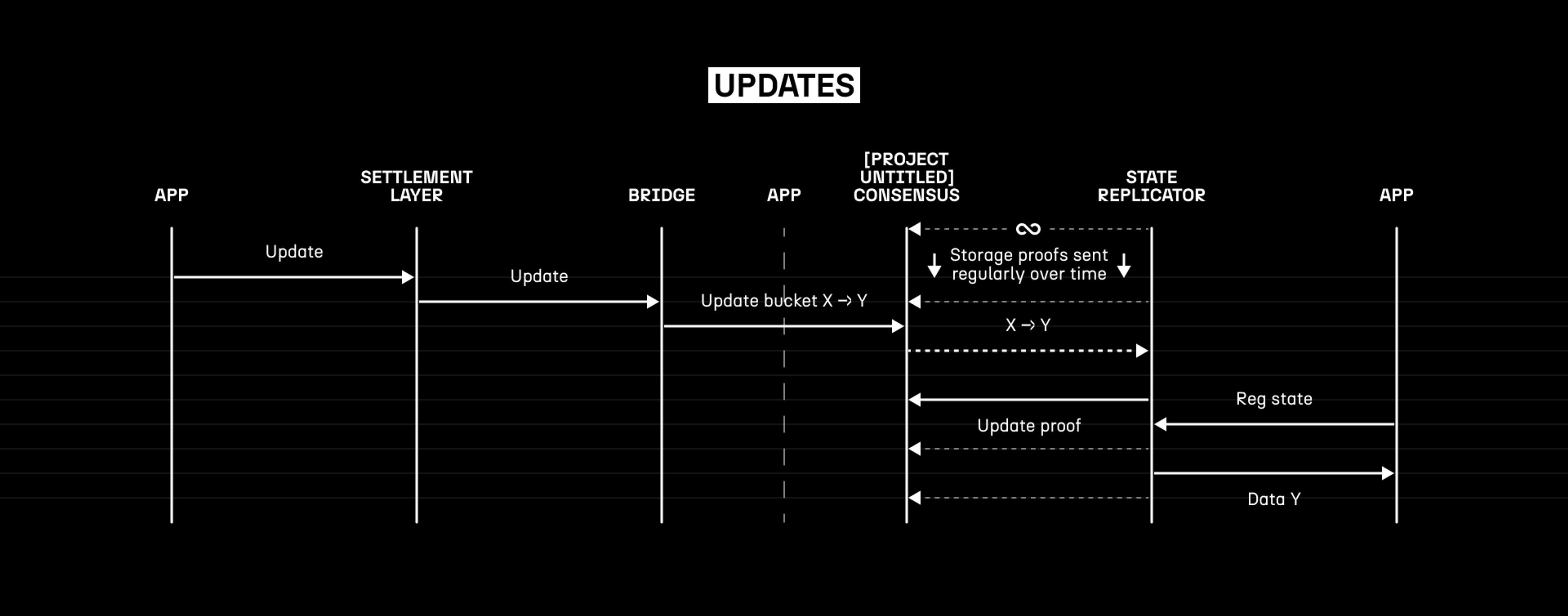
As the most common type of interaction for [Project Untitled], updates are comparatively simple. When an application needs to update its state, it can send an ‘update bucket’ message to [Project Untitled] with a proof authorising its contents. The state replicator will grab the updated data, and in place of its next ‘storage proof’ it will send an ‘update proof’, proving that the node is now holding the latest state after applying the diff.
To ensure that the state hosts are responsive to update requests, we can again use slashing to enforce that the state is updated within the given window. On the other side, once we have slashing for this mechanism, a malicious user of the application could refuse to provide the data that supports their update request. However, the system requires liveness of the state replicators for their correct operation anyway, so it is easy to operate a close-to-realtime dispute game when this happens.
Termination
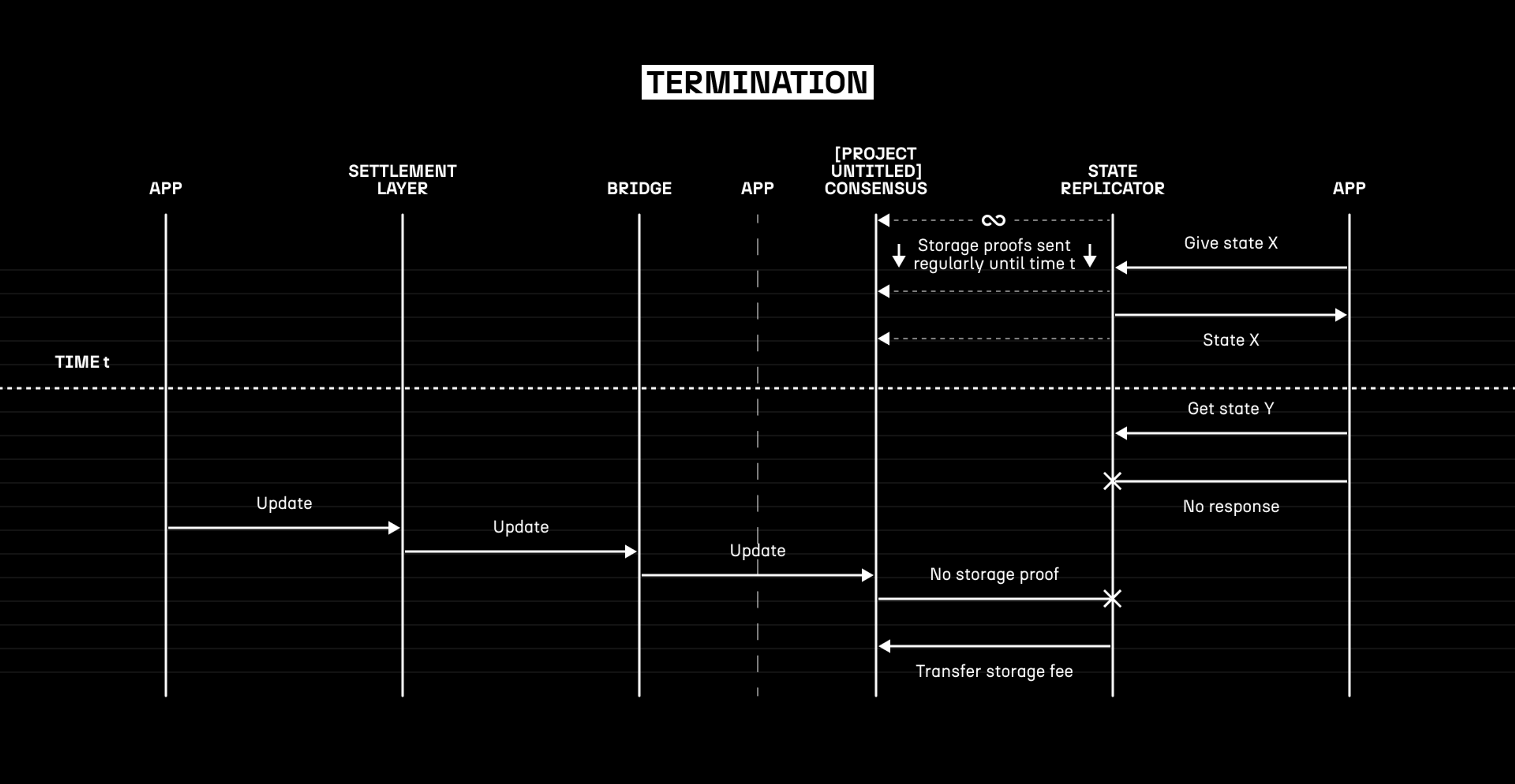
After the agreed-upon time period, the hosting contract will naturally end. If it is not renewed, the state host will no longer need to reply to any requests, and any update requests will be rejected by the network. At this stage, the locked bond for the host is released, and the host is free to delete any data that it was holding as part of the agreement.
Renewal
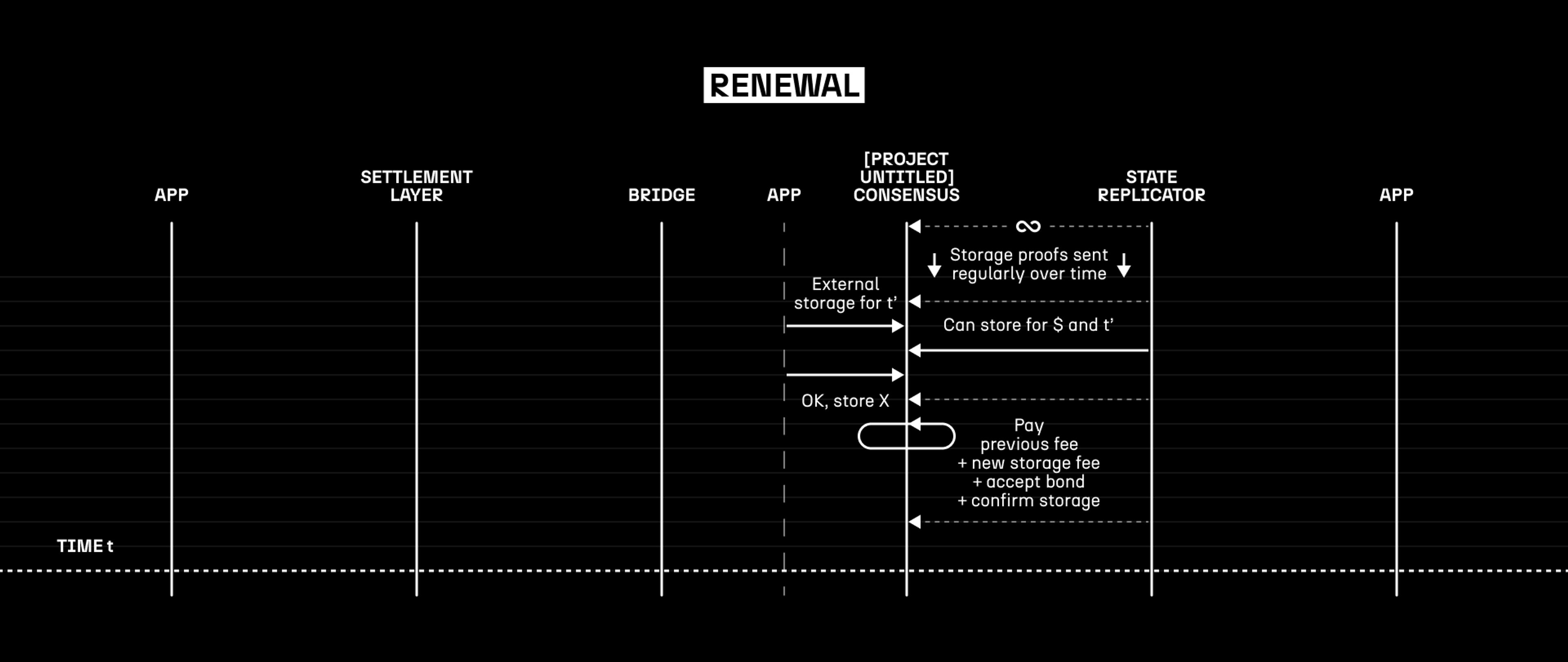
In the normal operation of [Project Untitled], we expect that many applications will want to continue holding their state essentially indefinitely. To make this even easier, we’re proposing a dedicated protocol to allow applications to renew or re-negotiate with their existing state hosts, so that there is no need to transition the entire application state to a different node or nodes. With our goal of keeping [Project Untitled] as cheap and easy to use as possible, we’re eager to make these most-common interactions as effortless as we can.
Succinctness
From our experience in building Mina, we know that succinct chains are the only sustainable way to run blockchain systems into the long-term. We already see the amounts of data required to sync to a node ballooning, and much of Web3 has been realising that rollups should be everywhere.
For [Project Untitled] in particular, the actions on the chain are intended to be close to realtime, and there’s very little value in a historical record of dispute games once they have been resolved. Recognising that we can re-use much of the technology that we’ve built for Mina, we’re confident that the best design is one that rolls all of the proofs into a single proof of the entire blockchain, making fully-trustless bridges easily available.
Interestingly, many of the actors in the protocol are already widely- and well-understood. We can follow Mina’s model of snark workers and block producers, and model storage and update proofs as transactions. This puts us in a good position to build this system the way it should be, in the timescale that developers need.
State replicators
The most different part of this system is the behaviour of the state replicators. While these nodes truly are participants in the network, they are special in the sense that they essentially send transactions on a timer, instead of extending the chain or producing snark work. Of course, to receive the random challenges that the chain will generate, they will need to participate in consensus to keep up with the chain; luckily, the succinctness that we’ve already covered gives them the ability to sync to and keep up with the chain without wasting storage that they could be providing to network users.
These nodes will be vulnerable to slashing of their bond if they fail to submit their storage proofs or to apply updates once requested. The particular details of the tokenomics require more research, but this slashing exposes these nodes to two attack vectors that we have identified: the block producers may choose not to include their ‘transaction’ containing the storage proof at that time, and applications may choose not to serve the data for their update after their update requests. For state replicators to be comfortable bonding in the network, we need to provide protection against both of these attacks.
Inclusion in blocks
In the Mina-style blockchain model, all of the transactions and the snark work proofs are sent inside the block bodies, to make sure that the data is available to all of the nodes. However, the incentives in this system are different enough that we can consider a different option for the storage proofs: mempool consistency.
Since each of the storage / update proofs is expected at a particular time, there will be a window where a state host can submit their proof and be confident that everybody in the network will have it by the time it is required for the block. By using this property, and rejecting any blocks that are missing proofs from the shared mempool, we can give complete confidence that no block producer can induce slashing if a valid, timely proof is available in the network.
Data transmission for updates
Ideally, when an update is requested, the requester will immediately provide the diff to any network participant who requests it, including the state replicators if they were to request it directly. Acknowledging that this will not necessarily happen, we can allow nodes to opt-in to operate as ‘relays’ for the state hosts, so that they can be used to forward the data to those state hosts, or to declare that the requester is not cooperating if they aren’t sharing with the network.
While the specific tokenomics needs more research, there are incentive models that should again give state replicator operators the confidence that they need to bond in the network.
What next?
For now, as we work towards the [Project Untitled] roadmap, we’d love to hear feedback on the technical design, any input for how we could work best with your applications, and any other reactions. You can find us on Twitter, contact us on Discord, or jump into our GitHub for the technicals.
Our engineering team will be working on the whitepaper, which will be published on this blog and on our website as it becomes ready. You can follow us here to get updates.
And finally, we are hiring! If this project sounds like something you would love to be involved with, we want to hear from you. You can find our job listings here.